Lecture 7: Reinforcement Learning
Markov decision process, policies, rewards, value functions, the Bellman equation, q-learning, policy learning, actor-critic learning, AutoML.
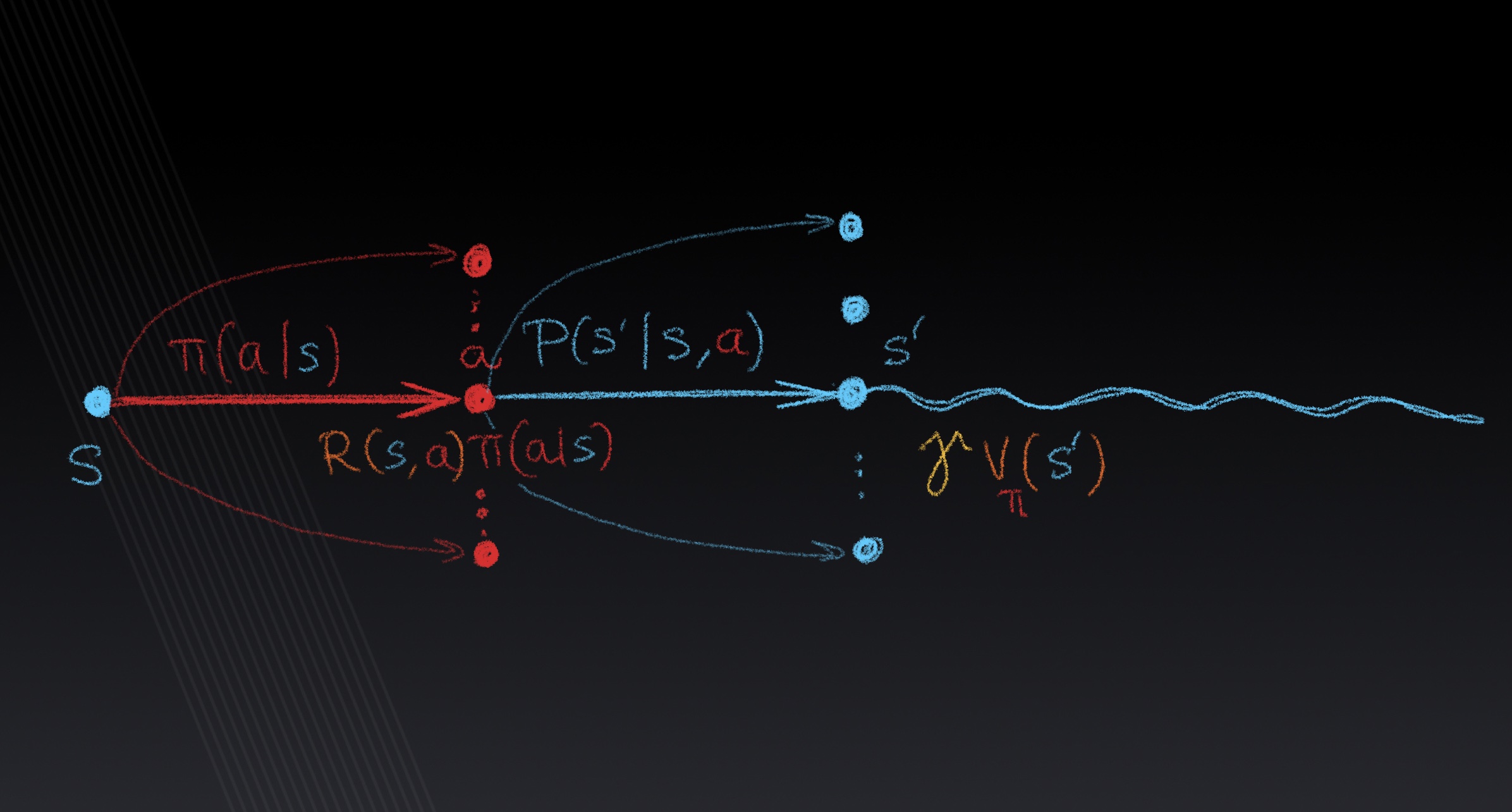
Slides
- Part A: Main lecture
- Part B: AutoML
Videos
- Part A: Main lecture
- Part B: AutoML
Lecture Notes
Accompanying notes for this lecture can be found here.